
谷歌实现“量子霸权”最强超算10000年?FAQ解答
【新智元导读】谷歌实现“量子霸权”的新闻最近沸沸扬扬,“量子计算机200秒,最强超算10000年”意味着什么?今天,著名理论计算机科学家Scott 就谷歌的“量子霸权”研究进行了FAQ解答,Scott曾是“D-Wave 首席怀疑官”,但他十分肯定谷歌的量子霸权研究。
最近,,打造出第一台能够超越当今最强大的超级计算机能力的量子计算机!
该计算机能够在 3 分 20 秒内执行一个计算,而同样的计算用当今最强大的超级计算机 进行,需要约 10000 年。这被认为是量子计算里程碑式的进展!
谷歌的论文一开始在NASA网站上发布,但不久被悄悄删除,但论文仍通过各种渠道流传,关于谷歌的“量子霸权”研究,我们也得以一窥究竟。

论文地址:
今天,著名理论计算机科学家、量子计算专家Scott 在个人网站就谷歌的“量子霸权”研究进行了FAQ解答,他认为谷歌的正式论文可能会在一个月内在某知名期刊(哪本期刊?选项可以缩小到2个)发表。Scott 分析了谷歌的量子霸权实验、量子霸权本身是否有任何应用、谷歌下一步是什么等问题。
Scott 何许人也?
Scott ,美国理论计算机科学家,德州大学奥斯汀分校计算机科学教授,量子信息中心主任。此前曾与麻省理工学院电子工程与计算机科学系任教多年,研究领域包括量子计算机的性能与局限,更广义的计算复杂度理论等。在MIT期间,Scott曾是姚班学霸陈立杰的导师。

Scott
在康奈尔大学获计算机科学专业学士学位,在加州大学伯克利分校获博士学位,在加拿大滑铁卢大学量子计算研究所做博士后研究员。2007-2016 年在麻省理工学院任教,2007 年秋任助理教授,2013 年春晋升为副教授。2016 年至今在德州大学奥斯汀分校任教,任全职教授。著有《德谟克利特以来的量子计算》。
他的个人博客 “-” 经常从科普向角度解答一些关于量子计算的问题,一直广受欢迎。他撰写的《谁可以命名更大的数字?》一文在计算机科学学术界中得到了广泛传播,文中使用了 Tibor Radó 所描述的 Busy 的概念来说明在教学环境中可计算性的局限性。

他讲授的面向研究生的调查课程《自德谟克利特以来的量子计算》的讲义已由剑桥大学出版社出版。书中将关于量子计算的不同主题编成一个整体,其中涵盖量子力学、复杂度、自由意志、时间旅行、人类准则等内容。
知名科普期刊《科学美国人》曾发表了他的《量子计算机的局限性》一文,他的观点和言论也经常被大众主流媒体所引用。
“量子霸权”15问:没有破解不了的密码了吗?非也
Q1:什么是量子计算霸权?
通常缩写为“量子霸权”( ),这个术语指的是利用量子计算机来解决一些定义明确的问题,而这些问题如果使用现有的经典计算机和已知算法来解决,需要的时间是数量级更长的。这不是偶然的原因,而是由于渐进量子复杂性。
这里的重点是,要尽可能确定这个问题确实已经被量子计算机解决了,并且确实对于经典计算机而言是棘手的,并且在理想情况下能够很快实现加速。如果这个问题对某件事也有用,那就更好了,但这完全没有必要。莱特飞行器和费米堆本身并没有什么用处。
Q2:如果谷歌真的实现了量子霸权,是否意味着正如民主党总统候选人安德鲁・杨( Yang)最近在推特上所说的那样,现在“没有什么密码是不可破解的”?
不是这样。(但我仍然喜欢杨。)
这里有两个问题。首先,目前由谷歌、IBM和其他公司制造的设备具有50-100个量子比特,而且没有纠错功能。运行 Shor算法来破解RSA密码系统将需要数千个逻辑量子比特。使用已知的纠错方法,可以很容易地转换成数百万个物理量子比特,而且这些量子比特的质量比目前存在的任何一种都要高。我认为现在没有人能做到这一点,我们也不知道需要花多长时间。
但第二个问题是,根据我们目前的理解,即使未来拥有可扩展的、有纠错功能的量子计算机,它们也只能破解某些密码,而不是全部。不幸的是,他们能够破解的公钥密码包括了我们目前用来保护互联网安全的大部分内容:RSA、-、椭圆曲线加密等等。但是私钥密码受到的影响应该很小。甚至还有一些候选的公钥密码系统(例如,基于的),经过20多年的尝试,仍然没有人知道如何进行量子破解。现在正在进行的一些工作,已经开始迁移到这些系统了。
Q3.:谷歌计划进行或已经完成了哪些通常认为经典计算机很难做到的计算?
它计算的是:一个“”生成一个随机量子电路C(即一个由1个量子比特和最近邻的2个量子比特组成的随机序列,深度为20,作用于n=50至60 的二维网格上)。然后,将C发送到量子计算机,并要求它将C应用于全部为0的初始状态,以{0,1}为基础来测量结果,并返回所观察到的所有n-bit字符串,并重复数千次甚至数百万次。最后,利用统计检验来来检查输出是否与量子计算机所做的一致。
所以,这不是一个因式分解问题。电路C在n-bit字符串上产生了一些概率分布,称为DC,问题是从这个分布中输出样本。事实上,通常会有2^n个字符串支持DC,如此之多,以至于如果量子计算机按预期工作,将永远不会观察到相同的输出两次。然而,关键的一点是,DC的分布并不均匀。虽然我们只会观察到与2^n相比很小的样本,但我们可以检查样本是否优先地聚集在预测更有可能的字符串中,从而建立起我们对完成传统上棘手的事情的信心。
一句话总结:量子计算机只是被要求应用一个随机(但已知的)量子操作序列——不是因为我们关心结果,而是因为我们试图证明它能在一些定义明确的任务上击败经典计算机。
Q4:但是,如果量子计算机只是执行一些随机的电路,其唯一的目的就是经典计算机难以模拟,那么有什么意义呢?这不是过度宣传吗?
不,当然有意义。
要对我们在这里所谈论的巨大规模,以及使它成为现实所需要的可怕的工程,有一点尊重。达到量子霸权之前,量子计算机怀疑论者可以嘲笑,因为花了数十亿美元、20多年,仍然没有一台量子计算机能比笔记本电脑更快地解决一个问题。在后量子霸权的世界,情况将不再是这样。
我再次提到莱特飞行器,因为我们正在谈论的内容与我在互联网上见到的人们的不屑一顾之间的鸿沟,对我来说非常令人惊讶。就好像,如果你坚信空中旅行从根本上就是不可能,那么看到一架木制螺旋桨飞机保持在高空飞行不会改变你的信念,但也不会让你感到放心。
Q5:几年前,你批评大众对D-Wave过于兴奋,而它声称通过量子退火可以极大地加速优化问题。但现在,你又批评大众对量子霸权不够兴奋。这是为什么?
因为我的目标不是朝着大众偏爱的方向发展“兴奋水平”,而是朝着正确的方向!事后看来,你会承认我对D-Wave的看法基本上是正确的,即使那让我在一些圈子里非常不受欢迎。我也在努力证明我对量子霸权的观点是正确的。
Q6:如果量子霸权的计算只涉及从概率分布中采样,你如何验证它们是否正确?
好问题!这是我和其他人在过去十年中发展起来的大量理论的主题。我已经在我对Q3的回答中给出了一个简短的版本:通过对QC返回的样本进行统计来验证,检验它们优先聚集在混沌概率分布DC的“峰值”。有一个简便的方法,谷歌称为“线性交叉熵检验”,就是将量子计算机返回的所有样本s1,…, sk的Pr[C si]相加,然后求和。当且仅当总和超过某个阈值(例如 bk/2^n, 常数b介于1和2之间)时,才声明测试 “成功” 。
诚然,为了应用这个测试,你需要在经典计算机上计算Pr[C si]的概率,而唯一已知的计算它们的方法需要蛮力,并且需要大约2^n的时间。如果n是50,并且你是谷歌,那么是有能力处理2^50这样的数字的。通过运行一个巨大的经典内核集群(比方说)一个月,你最终可以验证量子计算机几秒钟内生成的输出——同时还可以计算量子计算机快了多少个数量级。然而,这确实意味着基于采样的量子霸权实验几乎是专为目前正在建造的50量子比特设备而设计的。如果有100个量子比特,我们可能就不知道如何使用地球上所有可用的经典计算能力来验证结果了。
Q7:等等,如果经典计算机只能检验量子霸权实验的结果,在一个经典计算机仍能模拟实验(尽管速度极慢)的体制下,那么你怎么能宣称“量子霸权”呢?
对于一个53量子比特的芯片,在一个仍然可以直接验证输出结果的系统中,你完全有可能看到速度增加了数百万倍,同时你也可以看到速度随着量子比特的数量呈指数增长,这与渐近分析所预测的完全一致。
Q8:是否有数学证据证明没有任何快速的经典算法能够欺骗基于采样的量子霸权实验的结果?
不,目前没有。但这并不是量子霸权研究人员的错!只要理论计算机科学家不能证明P≠NP或P≠这样的基本猜想,就不可能无条件地排除快速经典模拟的可能性。我们所能期望的最好结果是 。
我们确实成功地证明了一些这样的结果——例如玻色子采样那篇论文,或者等人关于随机电路中振幅计算的平均情况#P-的论文,或者我与陈立杰合著的论文(“- of ”)。在我看来,这方面最大的理论开放问题是证明更好的 结果。
Q9:基于采样的量子霸权本身有什么应用吗?
人们第一次想到这个问题时,答案显然是“毫无用处”!不过,最近情况发生了变化,例如,由于认证随机性协议,显示了一个基于采样的量子霸权实验几乎可以立即被重新利用,从而生成可以被怀疑是随机的比特(在计算假设下)。反过来,这可能适用于持有量证明加密货币(proof-of-stake )和其他加密协议。我希望在不久的将来能发现更多这样的应用。
Q10:如果量子霸权实验只是产生随机比特,那不是很无趣吗?仅仅通过测量就能把量子比特转换成随机比特,这不是很简单吗?
关键是量子霸权实验不会产生均匀的随机比特。相反,它从一些复杂的、相关的、超过50或60位字符串的概率分布中采样。
Q11:数十年的量子力学实验——例如,那些违反贝尔不等式的实验——难道还没有证明量子霸权吗?
这纯粹是文字上的混淆。其他的实验证明了“量子霸权”的其他形式:例如,在违反贝尔不等式的情况下,你可以称之为“ ”。他们没有展示量子计算的优势,这意味着是不可能用经典计算机模拟的事情(在经典计算机模拟中没有空间局域性或其他类似的限制)。今天,当人们使用“量子霸权”这个短语时,它通常是量子计算霸权( )的缩写。
Q12、即便如此,目前仍然有无数材料和化学反应无法用经典方法实现模拟,而且现在也出现大量特定用途的量子模拟器。为什么这些都不算是实现了 “量子霸权”?
如果按照一些人对 “量子霸权” 的定义,确实已经实现了!这次谷歌实现的与他们的主要区别在于,有了完全可编程的设备,可以通过传统计算机发送适当的信号,使用任意序列的最近邻的 2 - 量子比特门进行编程。
换句话说,这下量子计算的怀疑论者肯定会不高兴了,可以肯定的是,有些量子系统很难用经典方法模拟,但这仅仅是因为大自然确实很难模拟,而且你不能把发现的什么化学物质随意重新定义为 “可以自我模拟的计算机。” 现在,在任何正常的定义下,谷歌、IBM 和其他公司正在建造的超导设备都的确是 “计算机”。
Q13、“量子霸权” 的概念是你发明的吗?
不是,但我在开发上发挥了一些作用,这导致萨宾・霍森费尔德( )等人误以为整个概念都是我提出的。“量子霸权” 一词是约翰・普雷斯基尔(John )在 2012 年提出的,尽管从某种意义上说,其核心概念可以追溯到 1980 年代初的量子计算本身。1994 年,使用 Shor 算法来分解大量数据成为 “量子霸权” 实验的手段,不过即使在现在,这个实验仍然很难执行。
使用采样问题来证明 “量子霸权” 的关键思想是由 和 David 在 2002 年发表的一篇有远见的论文中首次提出的。当时出现了一批论文,不仅表明 “简单的” 非通用量子系统可以解决看似困难的采样问题,而且面向相同采样问题的有效经典算法将意味着多项式层次结构的崩溃。即使是近似量子采样问题,用经典方法解决也是非常困难的。
据我所知,“随机电路采样” 的思路源于我在 2015 年 12 月发起的一次电子邮件对话,参与成员还包括 John , Neven, Boixo, , , Jozsa,Aram ,Greg 等人。该对话的标题为 “40 量子比特的硬采样问题”。
当时我们讨论了三种基于采样方法的 “量子霸权” 方法的优缺点:(1)随机电路,(2)通勤哈密顿量,以及(3)Boson 。在 Greg 提出支持方案(1)的意见后,我们迅速达成共识,即从工程学的角度来看方案(1)确实是最好的选择,即使理论分析仍不能令人满意,也可以补救。。
之后, 团队对理论和数值上的随机电路采样进行了大量分析,而 Lijie Chen、 和我则对此进行了分析,从理论上证明了用经典方法解决这类问题的难度。
Q14、如果量子霸权真的实现了,对于量子计算的怀疑论者而言意味着什么?
我现在可不想成为他们的一员!他们当然可以退一步说,量子霸权是可能实现的(谁敢说绝对不可能?),其实真正的问题一直是 “量子纠错”。确实,这些人中有些人始终保持这个立场。但是其他人,包括我的好朋友吉尔・凯莱(Gil Kalai)在内都曾经预测过,说出于根本原因,量子霸权不可能实现。现在把话收回去好像有点晚了。
Q15、下一步呢?
如果实现了量子霸权,那么我认为 团队已经有了必要的硬件来执行我提出的协议,生成认证的随机比特了。他们下一步确实计划这么做。
除此之外,显而易见的下一个里程碑将是可编程量子计算机的应用(如 50-100 量子比特),可以比任何已知的经典方法更快执行一些有用的量子模拟任务(如凝聚态系统)。此外,“量子纠错” 将走向应用,可以使编码的量子比特存活时间长于基础物理量子比特的存活时间。
毫无疑问,谷歌,IBM 等领跑者将朝着这两个重要里程碑迈进。
谷歌“量子霸权”的论文究竟讲了什么?MIT 量子物理博士生专业解读
尽管NASA在上线谷歌“量子霸权”的论文不久后悄悄撤下,这篇论文仍通过各种渠道流传出来。MIT 量子物理专业博士生(知乎 ID:少司命)从专业角度,以通俗的语言解释了谷歌这篇论文的主要内容。新智元经授权转载如下:
毫无疑问的是,这会是量子计算领域一个里程碑一样的大新闻.
9 月 20 号刚刚看到这个消息,据说是 NASA 发布到官网上而后又迅速删掉,但是内容已经在网上大规模流传开了。文章写的非常简单易懂,我尽量用简单的语言陈述一下这个新闻的主要内容吧 (蹭热度),如果没有任何背景可以只看加粗字体部分。如果哪里不准确欢迎指正补充。
首先一个概念,所谓的 ,有人翻译为量子优势也有人翻译为量子霸权,一般指的是量子计算在某一个问题上,可以解决经典计算机不能解决的问题或者是比经典计算机有显著的加速 (一般是指数加速)。
回到文章,在硬件方面,谷歌家一直用的是超导电路系统,这里是 54 个物理比特 () 排成阵列,每个比特可以与临近的四个比特耦合在一起,耦合强度可调 (从 0 到大概 40MHz),实物图和示意图分别如下。

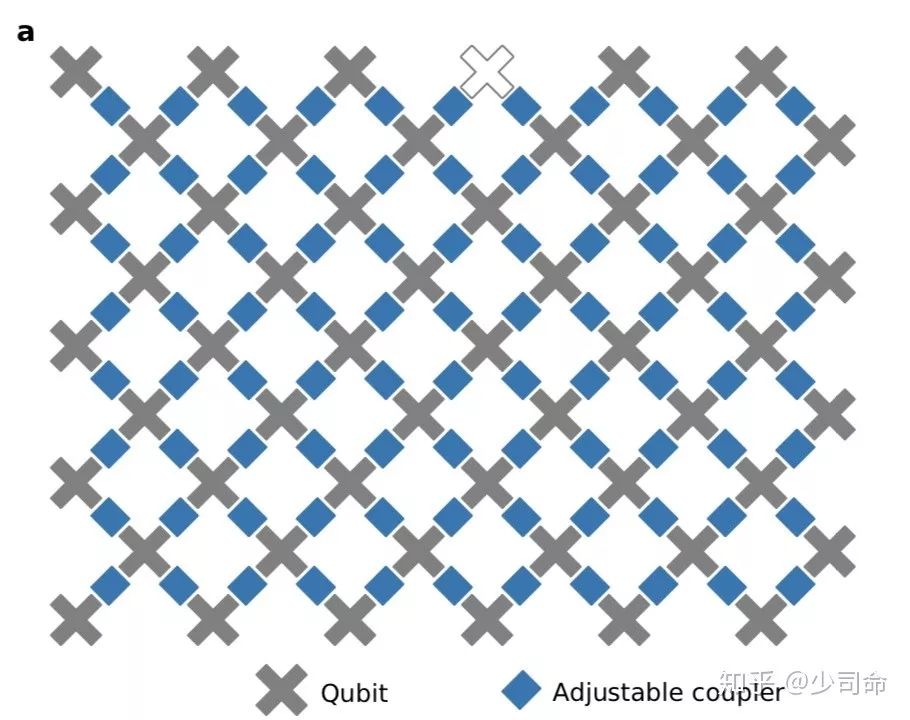
图中一个灰色的叉号就代表一个量子比特,蓝色的则是可调的耦合装置
有了硬件就要衡量其性能的好坏,所以首先要知道对这些量子比特进行操作时发生错误的概率 (error rates)。这里他们用 cross- (XEB) 的方法测量这些 error。XEB 早就有了我记得 在今年 3 月会议时候就讲过,跟 很像都是加一系列随机的门操作,然后从保真度衰减信号中提取出 error rates.
下图是他们最终得到的结果,在没有并行时候单比特 0.15% 的错误率其实不算高,而双比特 0.36% 的错误率 e2 有 0.36% 则还不错,像 另一个 18 比特的 我记得两比特的有 0.8%.
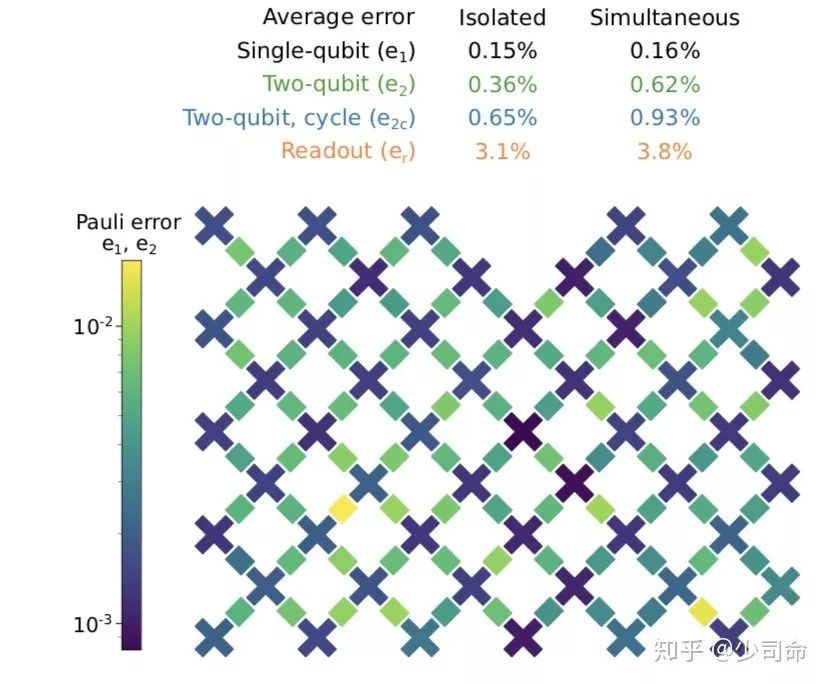
上面列了各个 error rate, 下面是 error 分布的 heat map.
下面是文章最重要的部分, 在多项式时间内实现了对一个随机量子电路的采样,而在已知的经典计算机上需要的时间则非常非常之久,像文中实现的最极端的例子是,对一个 53 比特 20 个 cycle 的电路采样一百万次,在量子计算机上需要 200 秒,而用目前人类最强的经典的超级计算机同样情况下则需要一万年。亦即在这个问题上,量子实现了对经典的超越。
这里的 cycle 指的是对这些比特做操作的数目,一个 cycle 包含一系列单比特操作和双比特操作,可以近似理解为电路的深度 ( depth)。对于最大的电路,即 53 个比特 20 个 cycle 的情况,在量子处理器上做一百万次采样后得到 XEB 保真度大于 0.1% (5 倍置信度),用时大概 200 秒。而要在经典计算机上模拟的话,因为比特数目很多整个的希尔伯特空间有
而且还有那么多电路操作,这已经超出了我们现在超级计算机的能力 ( time),就像文中举的另一个例子,用 SFA 算法大概需要 50 万亿 core-hour (大概是一个 16 核处理器运行几亿年吧), 加 Wh 的能量 (也就是一万亿度电...),可以想见是多么难的事情了。而量子这个问题上为啥会比经典好也非常容易理解,用到的就是量子运算的并行性,即量子态可以是叠加态可以在多项式时间内遍历整个希尔伯特空间,而经典计算机模拟的话需要的资源则是随着比特数目指数增加的。
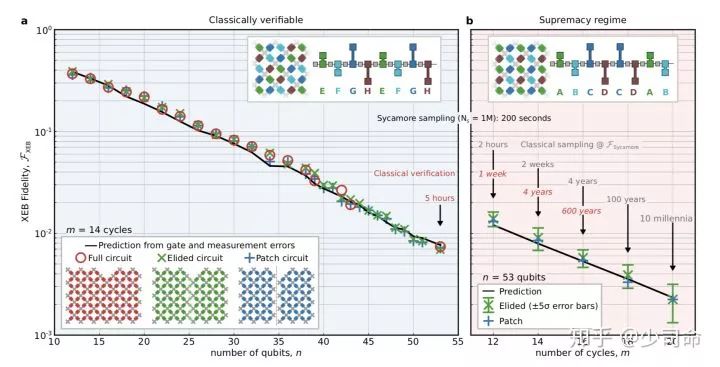
左边图 a 是经典计算机可以模拟的区域,右边图 b 则是量子有优势的区域。红色数据点为最复杂的电路,绿蓝代表两种稍作简化后的电路。
当然有没有可能是有些更好的经典采样算法和量子的差不多,只是我们没有找到呢?文中没有给出很直接的回答,他们认为从复杂度分析来讲经典算法总是会随着比特数和 cycle 指数增加的,而且即使未来有一些更好的经典算法,到时候量子的处理器也发展了所以还是会比经典的好。
最后个人的一点 ,振奋的同时也要保持清醒,我们离着实现量子计算的完全功力还有很远的距离。硬件上有集成化的问题,比如这里的超导比特系统要加微波 要谐振腔 ,比特数目增加后有空间不足和 cross-talk 等各种问题,远远不止我们图中看到的一个小芯片那么简单;再一个比特数多了电路深度大了怎么继续提高保真度也是很大问题,像这篇文章里 53 个比特到第十几个 cycle 时候保真度只有 10 的负二次方量级了,怎么 error 实现量子纠错,最终实现容错量子计算等等,这些都是硬件上的挑战;
算法上,除了这里的采样问题(由此延伸的可以解决的问题其实是非常有限的),又有哪些问题是可以证明量子比经典有显著优势的,可不可以设计一些算法使得量子计算机能解决经典不能解决的问题,或者量子比经典有显著的加速,就像文章最后所说的:
...As a of these , is from a topic to a that new . We are only one away from near-term .
在 NISQ (noisy- scale ) 的时代 (如下图),虽然我们离绿色真正的容错通用量子计算机还很远,但是现在已经开始进入到蓝色区域相信在未来几年会有一些有趣的 near-term 的应用出现。
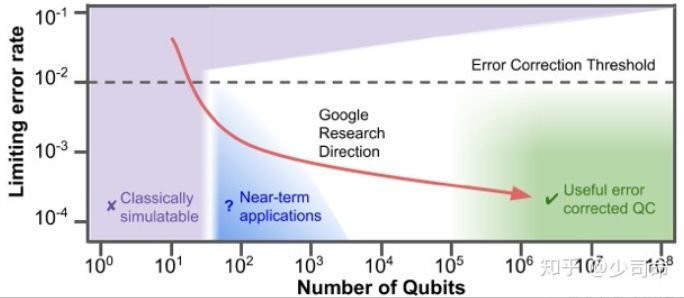
横坐标比特数目越大越好,纵坐标错误率越小越好
回答一下大家关心的问题吧,以下是个人观点:
一个是中国在这方面有什么进展,我们国家在近些年在量子方面投入很大,很多组也做出了许许多多非常突出的贡献,但必须承认的是,至少在我们在文中提到的用超导比特去做通用量子计算机这方面确实还有着比较明显的差距,但是道路是曲折的前途是光明的,我相信国内一定会迎头赶上并在很多领域做出超越的。现在无论学校科研院所还是大企业都有投入和发力,只不过具体方向会不一样很多优秀的成果也没有得到媒体的关注。
再一个问题就是很多同学表示还是看不太懂,确实没有相关背景了解起来会比较吃力,既准确又通俗的科普是件很难的事..., 还是我在文中强调的,文章的内容是量子计算重要的一步但是其应用是非常非常有限的,以后的路仍道阻且长,我们离着可以破解 RSA 密码离着量子计算机的大规模普及还很远,而且量子计算机也是不可能取代现在用的经典计算机的,这些应该是现在的业内共识。
参考链接:












